Git TFS Visual Studio Integration
As Git repositories are getting more popular, I write this post in the aim to review the two main type of repositories (Version Control System), what is Git and how they are supported by Team Foundation Server and Visual Studio.
The two types of Version Control Systems (VCS)are:
1. Centralized Version Control System (CVCS)
Centralized Version Control Systems follow a client/server architecture. The repository lives on the server, a central location that all collaborators connect to do all or most of their repository operations. The code history consequently resides on the central server.
This centralized architecture of Version Control is implemented in Team Foundation Server by the Team Foundation Version Control – TFVC – implementation. It is how TFS has been implemented since its first release, Team Foundation Server 2005.
1.1. TFVC Server Workspace: Check-in / Check-out Model
All developers are familiar with traditional Version Control Systems such as CVS, SVN, Visual SourceSafe, Team Foundation Server (TFS) to name some of the most popular. They are all Centralized Version Control Systems (CVCS) and have in common that we must ask the central system (the repository) permission to edit a file.
When we get the code base from the central repository, all files are ready-only. We must then ask the server authorization to edit the file by executing a check-out operation. If authorization is granted by the central repository, the read-only flag on the file is removed. We edit the file and when we want to integrate it with the code base on the server, we do a check-in operation. If nobody else changed the file, it is saved in the repository right away, otherwise we need to resolve conflict before saving. This is what is called the “Check-in / Check-out” model.
The check-in / check-out models is thus not designed to work offline as we need access to the repository server to be able to work.
This is the model that has been around since the first Version of TFS (2005) and also in its predecessor Visual SourceSafe.
Note on working offline with server workspace:
As server workspace always need to be connected to TFS, opening a Visual Studio solution without having access to TFS will prompt the user to go in offline mode which then allows us to edit the file, but it is not a seamless experience as we need to do some extra manual step: choose to “go offline” -> overwrite file -> go online -> reconcile -> check-in. As we can see, the Check-in / Check-out pattern for working offline is broken and so it is not an ideal situation. If we need to work offline, it would be better to have a different pattern that works the same way whatever we are online or not. This is what the Edit / Commit Model tries to solve for CVCS. DVCS solves that even better due to its architecture.
1.2. TFVC Local Workspace: Edit / Commit Model
Up until TFS 2012, the check-in / check-out model was the only model supported. There was only one type of workspace, the server workspace which was simply called “workspace” as no other type of workspace existed yet. If the old documentation (for TFS 2005, 2008, 2010) sometimes talk about “local workspace” it only means the folder on your local drive but the workspace itself is actually a server workspace when translated in the new nomenclature.
Since TFS 2012, it is possible to use local workspaces which allows working with TFS temporarily offline while offering a better user experience than with server workspace. Note that due to their client / server architecture, CVCS are not designed for working offline so it will never solve all problems and does not offer a full offline experience but it nevertheless provides a more seamless one.
When we get the code base from the central repository, all files are writeable (no read-only file attribute) which means that it is possible to edit a file without asking permission to the server. While offline, we can also undo uncommitted changes locally and compare the current version of a file with the last version we had before starting to modifying it.
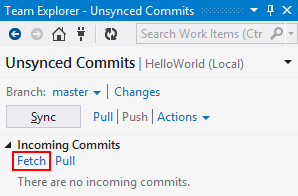
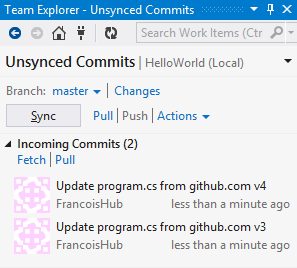
Nevertheless, commits are executed against the central repository (TFS). So, while local workspaces allows us to work disconnected from the server by allowing us to edit files, it is still a Centralized VCS and we must commit to the server. As a result, file change history is still stored centrally in the server. Consequently, many operations cannot be executed offline: creating branches, looking at file history, etc… and therefore local workspaces offer limited offline features beyond being able to edit files while offline.
The list of supported local operations is detailed in the following blog post: Server workspaces vs. local workspaces
On a performance point of view, a disadvantage of local workspaces is that when committing changes to the central repository, the tool will have to scan the entire copy of the code to be able to see which file has changed. This makes that local workspaces do not scale as well as server workspaces for very large code base. By that Microsoft means workspace containing more than 100,000 items! A quite uncommon scenario.
To use local workspaces in Visual Studio, we just need to go to edit the workspace, go to the advanced section and change the Location property to Local. See instructions on MSDN: Create and work with workspaces
Local Workspace vs Server Workspace – best practice:
While local workspaces have limitation when working offline (especially compared to DVCS), it still gives advantages compared to working with server workspaces. Microsoft actually recommends using local workspaces instead of server workspace. See MSDN article Decide between using a local or a server workspace
2. Distributed Version Control System (DVCS).
Distributed Version Control Systems follow a distributed architecture where there is no technical difference between any node running the Version Control System. The complete repository system is distributed among each user by which we mean that every user has a complete copy of a fully functional repository. There is no concept of client having to connect to a server to commit code. This fully functional repository is named the local repository as it is local to every team member.
Advantages of distributed repositories is tat we can do many more things offline than with TFS’ local workspaces. We can create branches, compare version of files, commit changes and so on while being offline. It is worth repeating that every developer has a full Version Control System working on their machine as it is quite a departure from preconceived ideas and old habits that a Version Control System should have a central storage.
Another advantage of DVCS is its performance: as everything is local, no operation has network overhead and no central system must share its resource to various users. Most operations will seem instantaneous.
Having a full copy of the repository also means that when we get code from a repository, we get all the files but also all the history – this can be slow the first time if the project is already large and has a lot of history, but it’s only on the first time as afterwards only changes will be exchanged between repositories .
2.1. Collaboration with DVCS
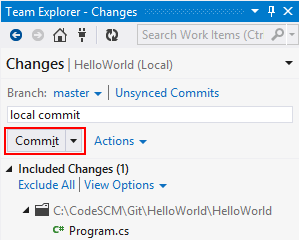
As everybody commit code locally, integrating everyone’s code is made in a separate operation. In contrast, for a CVCS such as TFVC, integration is made together with the check-in operation (merge operation).
Due to the distributed nature of the DVCS (comparable to peer-to-peer technology), programmers could theoretically collaborate by exchanging set of changes directly from one another. This would nevertheless prove cumbersome in practice as we would have to understand what other team members are working on and everybody would have to keep their computer online all the time so that we can get changes from them at any time we want. This last point would defeat one of the purpose of a DVCS which is being able to work offline.
Therefore, in practice, a repository node is set up and dedicated to code integration so that collaboration is eased. That intermediate is called the remote repository (as opposed to everyone’s local repository). All collaborators use the remote repository to push their set of changes to and to pull other people’s set of change. As the remote repository is in the form of a server supposed to be running all the time, collaboration is always possible no matter which collaborators are offline.
3. CVCS vs DVCS, how to choose?
CVCS suits best non-distributed team; meaning team members are (mostly) always online and have access to the CVCS server (mostly) all the time with a reliable and fast network connection. A typical example is a team within an office having TFS running in the corporate network.
With a CVCS, we need to be online to be able to work (so that we can check-out files). Local Workspaces solve this limitation but bring other limitations as they do not offer a full offline experience. Local workspaces still use TFVC (Team Foundation Version Control), which is a CVCS and will never be able to offer full offline experience due to its architecture.
In short: with CVCS, team members develop online.
DVCS suits best for highly distributed teams; meaning that team members can be geographically distributed and/or offline for some time or not having fast or reliable internet connection. DVCS permits to develop offline with a fully feature Version Control System and so we don’t have to be online to work, we only need to be online when we want to integrate our code with the code of other team members.
In short: with DVCS team members develop offline and integrate online.
4. What is Git?
Git is a Free and Open Source Distributed Version Control System.
Git is probably the leading DVCS tool and has great support amongst the open source community and across platforms (Linux, Mac, Windows). It is also supported in Visual Studio since Visual Studio 2012 Update 3.
Apart from being distributed, the main difference between Git and a standard control system (SVN, TFVC…) is that versions are not made of file-based changes, instead each version is a snapshot of a mini filesystem. See the Git Basics documentation for more information about Git’s storage mechanism.
If you want to learn more about Git, you can start at the Git documentation.
5. Git and Visual Studio
- Visual Studio 2010 and under: Git is not officially supported by Microsoft.
A Visual Studio extension nevertheless exists on CodePlex for Visual Studio 2010 and 2008. It is called the Git Source Control Provider and is available here (look for the “How to use” section which describes to install it through Visual Studio Tools Extension Manager by searching the online gallery for “Git Source Control Provider”)
- Visual Studio 2012: Git is officially supported by Microsoft.
Git repositories are supported by Visual Studio 2012 (uppdate 3 or higher) but it is not included out-of-the-box with the product: A Visual Studio extension for Team Explorer to provide source control integration for Git needs to be installed. This extension has been implemented by people working in the TFS team at Microsoft.
The Visual Studio 2012 extension is available here: Visual Studio Tools for Git and is in the form of an executable windows installer file: Microsoft.TeamFoundation.Git.Provider.msi.
The only prerequisite to install the extension is that Visual Studio 2012 Update 3 or higher is installed. At time of writing Visual Studio 2012 Update 4 is available here.
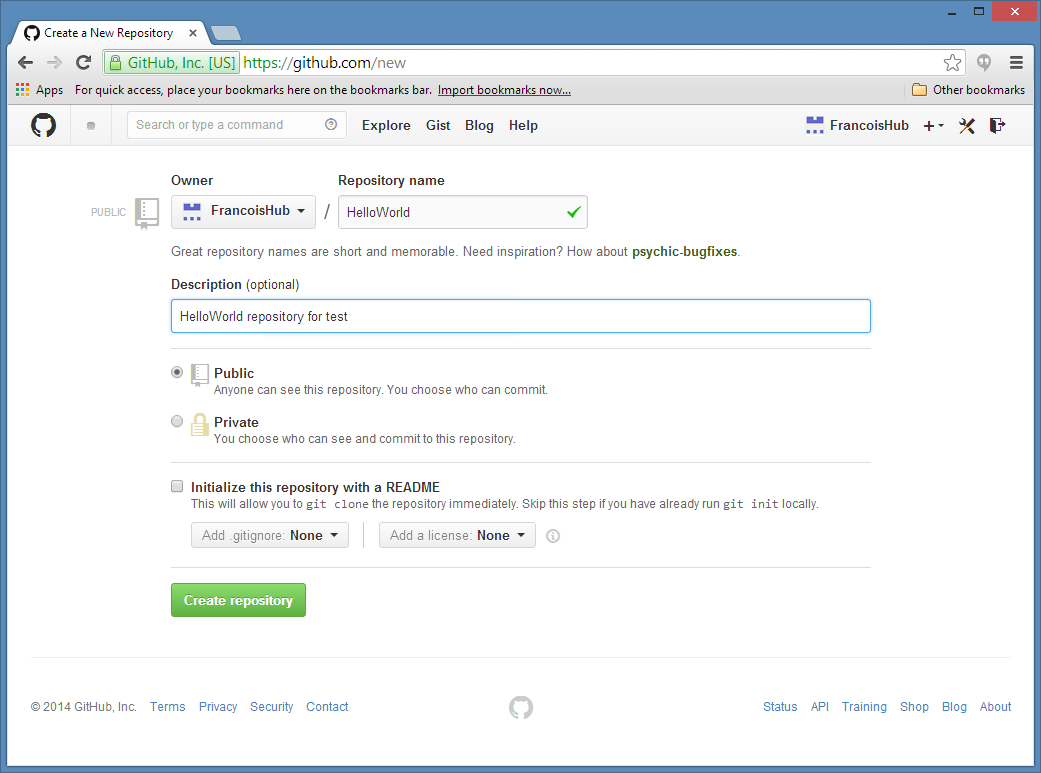
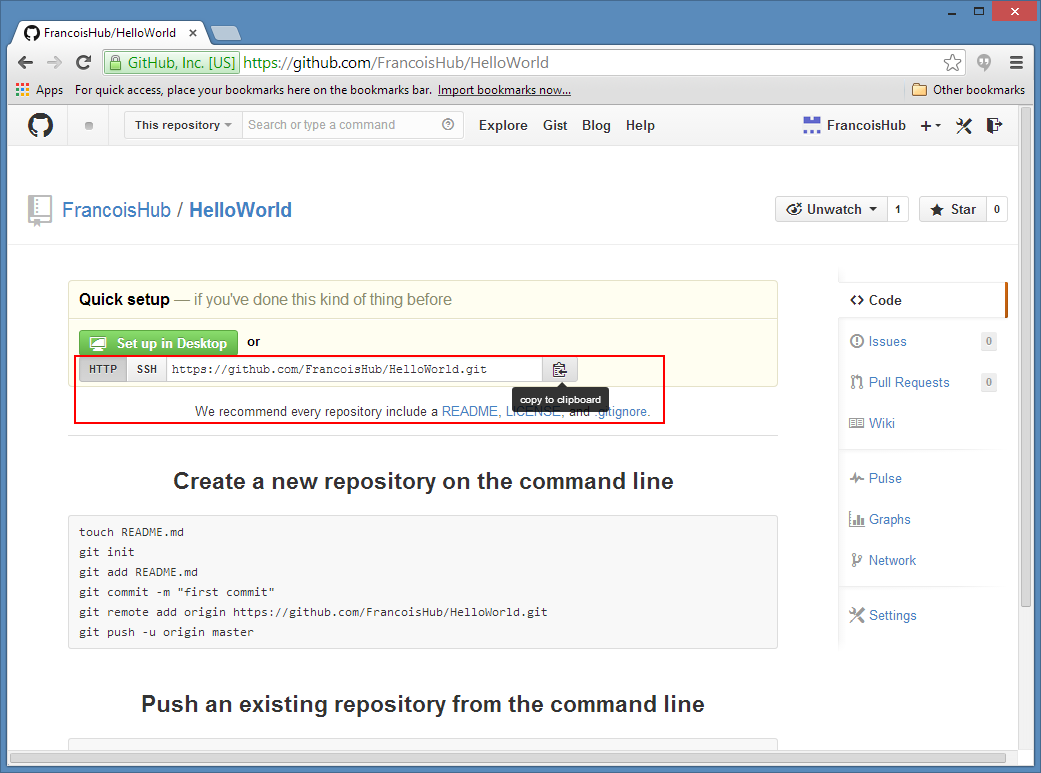
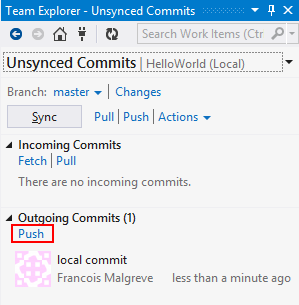
Here is a screenshot of installing the Visual Studio 2012 extension:
- Visual Studio 2013 ad above: Git is officially supported by Microsoft.
Git repositories are supported out-of-the-box in the product and no extension is required.
6. Git and TFS
Team Foundation Server 2013 is the first version of TFS giving the choice to run as a CVCS (TFVC repository) or DVCS (Git repository). TFS 2013 is thus able to host standard Git repositories.
An advantage of using a Git repository (on top of being distributed) is that it enables the numerous third party tools and development environment supporting Git to use TFS Git as their repositories. For example, a company working with multiple technologies could use TFS to host all their code regardless they are web applications developed using Visual Studio or iOS apps developed with Xcode.
It is great to see that TFS 2013 and Visual Studio support standard Git so that it is fully interoperable with other platforms and tools. It looks like Microsoft embraced the open source standards instead of writing their own Distributed Version Control System or worst, their own flavour of Git.
7. TFS in the cloud – Visual Studio Online
Microsoft has also launched the availability of a web-hosted version of TFS in the cloud. It was previously called Team Foundation Service and has now been renamed Visual Studio Online. As with on-premise TFS, it is an ALM (Application Lifecycle Management) on top of being a Version Control System. It is available on www.visualstudio.com.
A Microsoft Account (aka a Windows Live ID) is used to create a Visual Studio Online account. Basic accounts are free for up to 5 users (every additional users must be paid). Different account types exist if more features/tools are necessary. If a team needs a paid account, the Visual Studio Online account will have to be linked with a Windows Azure account through which billing will occur. For more information on pricing, see: Visual Studio Online Pricing Details.
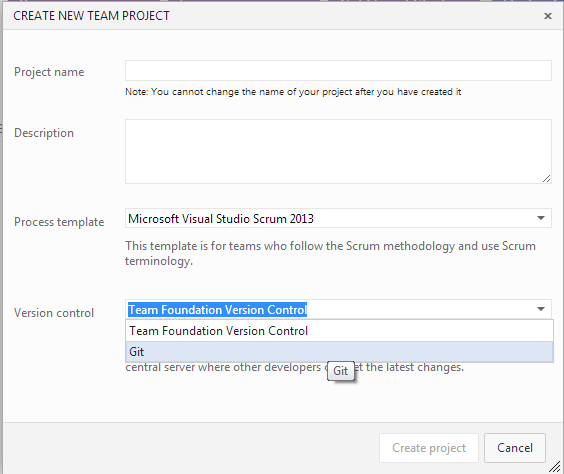
As with TFS 2013, Visual Studio Online can host either a TFVC or a Git repository.
In the screenshot hereunder, we can see that when creating a new Team Project on Visual Studio Online, we can choose the Version Control type, either TFVC or Git: