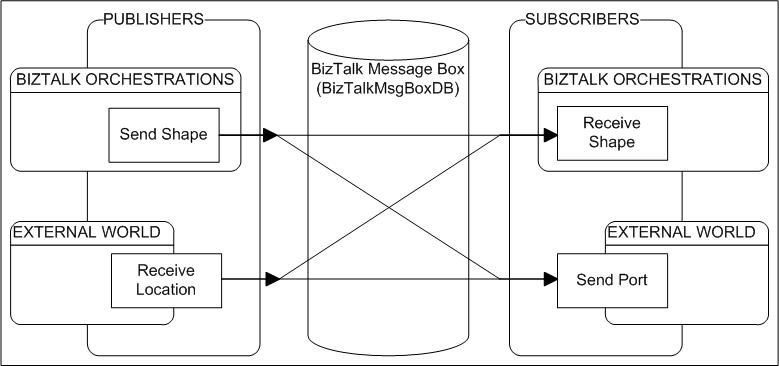
The core of the BizTalk Server product is the BizTalk Messaging subsystem, called the Message Bus. As said in the BizTalk documentation, The Message Bus is a publisher/subscriber model; indeed the Message Bus queries messages published into the BizTalk Message Box database looking for messages that match a particular subscription.
The most important point to understand about the publisher/subscriber model is that publishing and subscription concepts are relative to the Database.
Here is a picture illustrating the concept:
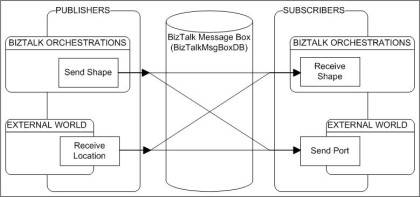
The Messaging infrastructure is composed of the Message Box database and also different software components, called the Messaging Components. The Db and the components together compose the publisher/subscriber BizTalk Messaging subsystem, the Message Bus.
An important side effect of this architecture is that in BizTalk Server, messages are immutable once published (in the Message Box DB). This is because more than one end-point can subscribe to the same message. Would messages be mutable, some end-points might not match the subscriptions rule after the message has been modified. Having the subscription query result vary with time on the same message (due to change in the message payload) would break the publisher/subscription architecture thus making the whole BizTalk product unpredictable (and so useless).
1. The Message Box.
The Message Box is an SQL Server database which stores XML messages as well as metadata related to each messages. The message’s metadata is called the message context. Each metadata item (a key/value pair) of the message context is called a context property. The most important information to know about the message context is that it holds all the necessary information for message routing – message subscription.
2. Messaging Components.
While the Message Box database is the message storage facility of the Message Bus, the messaging components are software components that actually move messages between subscribers and publishers. They receive and send messages in and out of the BizTalk Server system.
2.1 Host Services.
A BizTalk host is a logical container. It provides the ability to structure the BizTalk application into groups that could be spread across multiple processes or machines.
When you create a host in BizTalk server, it creates a logical unit in which you can run different BizTalk applications or different type of BizTalk artifact.
For example, if your BizTalk applications are pretty small, you could create 1 host per BizTalk application you develop. On the opposite if your applications are big, you can create different hosts to separate logical grouping of your application, such adapters, orchestrations, ports and so on. If each host runs on a separate physical machine this help in balancing the load between processors (some sort of manual load balancing).
A host instance is simply a running instance of the host logical grouping. It runs as a Windows Service, each host being a separate windows process; a separate instance of BTSNTSvc.exe (or BTSNTSvc64.exe for BizTalk Server 64 bit).
As explained before, the host instance raison d’être is to provide logical grouping units. It does not implement itself the BizTalk runtime, it is a container where the BizTalk subservices run. These subservices running inside the host instance implements together the actual runtime of the BizTalk Message Bus.
Host instances can run all BizTalk subservices or only some of them depending on what type of BizTalk artifacts they are running. To understand which subservice is used by which type of artifact, here is a list of the different subservices running inside a BizTalk host instance – note that the list of services can be found in the the adm_HostInstance_SubServices table in the Management Database:
| Service |
Description |
| Caching |
Service used to cache information that is loaded into the host. Examples of cached information would be assemblies that are loaded, adapter configuration information, custom configuration information, etc. |
| End Point Manager (EPM) |
Go-between for the Message Agent and the Adapter Framework. The EPM hosts send/receive ports and is responsible for executing pipelines and BizTalk transformations. The Message Agent is responsible to search for messages that match subscriptions and route them to the EPM. |
| Tracking |
Service that moves information from the Message Box to the Tracking Database. |
| XLANG/s |
Host engine for BizTalk Server orchestrations. |
| MSMQT |
MSMQT adapter service; serves as a replacement for the MSMQ protocol when interacting with BizTalk Server. The MSMQT protocol has been deprecated in BizTalk Server 2006 and should only be used to resolve backward compatibility issues. |
2.2 Subscriptions.
In a publish/subscribe design, you have three components:
- Publishers
- Subscribers
- Events
Publishers include:
- Receive ports that publish messages that arrive in their receive locations
- Orchestrations that publish messages when sending messages (orchestration send shape)
- Orchestrations that start another orchestration asynchronously (start orchestration shape). On a side note, the call orchestration shape does not publish the message into the Message Box, the message is just passed as a parameter.
- Solicit/response send ports publish messages when they receive a response from the target application or transport.
Subscriptions:
Subscription is the mechanism by which ports and orchestrations are able to receive and send messages within BizTalk server (see picture above).
A subscription is a collection of comparison statements, known as predicates, comparing the values of message context properties and the values specific to the subscription.
There are two types of subscriptions: activation and instance.
An activation subscription is one specifying that a message fulfilling a subscription should create a new instance of the subscriber when it is received. Examples of things that create activation subscriptions include:
- Send ports with filters
- send ports that are bound to orchestrations
- orchestration receive shapes that have their Activate property set to true.
An instance subscription indicates that messages fulfilling the subscription should be routed to an already-running instance of the subscriber. Examples of things that create instance subscriptions are:
- Orchestrations with correlated receives.
- request/response-style ports waiting for a response.
It is also important to know that when you define filter criteria on a send port, you are actually modifying the subscription of the port. As a reminder, filter expressions determine which messages are routed to the send port from the Message Box.
Enlisting:
The process of enlisting a port simply means that a subscription is written for that port in the Message Box. Consequently, un-enlisted ports do not have subscriptions in the Message Box.
The same is true for other BizTalk artifacts. An un-enlisted orchestration is an orchestration ready to process messages but having no way to receive messages from the Messaging Engine as no subscription is created for it yet.
The difference between an un-enlisted artifacts and a stopped artifacts is that ports and orchestrations that are enlisted, but not started, will have any messages with matching subscription information queued within the Message Box and ready to be processed once the artifact is started. If the port or orchestration is not enlisted, the message routing will fail, since no subscription is available and the message will produce a “No matching subscriptions were found for the incoming message” exception within the Windows Event Log.
Typical port usage with an orchestration:
What happens in an orchestration that as a send shape connected to a logical port which is in turn bound to a physical port, is that the message sent by the send shape will have a TransportID context property set to a value that matches the physical port TransportID. As the TransportID uniquely defines the port, this mechanism assures that the physical port will always receive the messages coming from the orchestration. It does not mean that only that port will receive the message as due to the nature of a publisher/subscriber architecture, any other port having a subscription matching the message context will also receives the message.
2.3 Messages
As said earlier a Message is more than just an XML document. It is actually a message containing both data and context. To be more precise, a message is composed of context properties and zero or more message parts.
Keep in mind that message parts are not always XML document. If the message is received through a port using the pass-through pipeline, the message can be any kind of data including binary data. On a side note, a pass-through pipeline does not promote context properties; this makes sense as the message is not even supposed to be XML in a pass-through pipeline, so it is not possible to evaluate XPath expression on the message to determine the value of the context property.
As said earlier a message is immutable once it is published. This means that once stored in the MessageBox DB, it can’t be changed. A message can nevertheless be changed once it is out of the database. In a receive pipeline component, a message can be modified before it is published in the MessageBox. In a send pipeline component, a message can be modified after being received from the MessageBox. A typical place to create or modify a message is also inside an orchestration.
2.4 Message Context Properties
Message context properties are used for the subscription mechanism (routing the message to its appropriate end point). They are defined in a property schema. At runtime, the property values are stored into a context property bag.
The property schema is associated with the message schema within BizTalk so that every inbound schema-based message has a schema and a property schema attached to it.
The property schema consists of a global property schema that every message can use by default and of an optional custom property schema which can be created to define application-specific properties. Both types of properties are essentially the same at runtime and both are stored in the context property bag.
So, both types of properties can be used by the subscription mechanism to evaluate which endpoints have a subscription matching the message. The most common subscription is based on a global property called the messageType which is a combination of the XML namespace of the message and the root node name separated by a # character. Ex: http://www.abc.com#RootElementName.
Using subscription to route documents to the proper endpoint is called Content Based Routing (CBR).
For information, if the message is not schema-based, there will be no MessageType property value. Such is the case for binary data message.
Message context properties are populated by the BizTalk runtime in 2 artifacts:
- The adapter writes and promotes into the message context properties related to the location, adapter type, and others properties related to the adapter.
- The Receive Pipeline can write and promote properties into the message context in any of its pipeline components. Disassembling components are of particular interest because they promote the messageType property which is commonly used for Content Based Routing.
Property bag.
It is possible to use the BizTalk API in pipeline component code to read/write context properties from the property bag. The property bag is an object implementing the IBasePropertyBag interface. If you intend to use that interface in a custom pipeline to write properties that will be used for routing, you have to keep in mind that properties that are simply written into the property bag using the Write() method are not available for routing. To have a property available for routing, you need to promote the property with a different API call, the Promote() method. This method writes the property and its value in the property bag but ALSO flag the property as promoted and so make it available for routing.